
Lets build a Database from scratch
build a database SQLight (inspired by SQLite) in Go

I find databases like SQLite fascinating. They power countless applications. They're simple and lightweight, yet surprisingly robust.
SQLite manages data persistence, querying, and concurrency all in one file. This means anyone can use it easily, without needing a big server setup.
Naturally, I became curious about how it all works under the hood.
What better way to dig into it than by building a SQLite-like database from scratch?
Why We Are Building a SQLight?
Developing our database system from the ground up enhances our grasp of storage, indexing, and how queries are executed.
We could also play around with performance tuning and unique data models) can be invaluable.
I didn’t know how a replicate concurrency or recovery works under the hood.
So wanted to give it a try to understand the full picture of it.
SQLite is a relational database. It stores data in tables and supports SQL-like queries. Everything is kept in a single file.
We will create a similar version using GO. It will have no dependencies except for the standard library. By the end, we will have a functional database that can store, retrieve, and manage data. Let’s dive in.
(Btw, if the code formatting bugs you, Please refer to the GitHub repo for full version)
🥳🥳You can see the complete code here in this github repo and demo below.
PS: If you would like to contribute to the repo, you are always welcome.
Here is the agenda
- 📌 Agenda
- 📂 Embedded Database
- 📌 Requirements and Scope 📝
- 🏗️ Architectural Overview
- 🛢️ Storage Engine
- 🗂️ Data Model and Schema Management
- 🔍 SQL Parsing and Query Interpretation
- ⚙️ Query Execution Engine
- 🔄 Transaction Management and ACID Compliance
- 📜 Recovery and Journaling
- 📊 Query Optimizer
- ⚡ Concurrency and Multi-threading
- 🔌 API Design and External Interfaces
- 🚀 Performance Tuning and Benchmarking
- 🔒 Security and Data Integrity
- 🛠️ Building the actual Database (SQLight!)Overview of Embedded Databases:
Embedded databases are self-contained systems that integrate directly with applications. They offer low-latency access and minimal configuration overhead. SQLite is a prime example and is widely used due to its simplicity and reliability. There are various categories of it and some of them are listed below.
database systems with differing application programming interfaces (SQL as well as proprietary, native APIs)
database architectures (client-server and in-process)
storage modes (on-disk, in-memory, and combined)
database models (relational, object-oriented, entity–attribute–value model, network/CODASYL)
target markets
2. Requirements and Scope
We will gather all the requirements and scope for our project most of the references are taken from SQLite DB.
Not all the requirements will be developed into a code but it will be good to understand.
Functional Requirements:
Data Storage: Ability to store and retrieve data in a persistent file.
SQL Interface: Support for a SQL dialect that includes DML (INSERT, SELECT, UPDATE, DELETE) and DDL (CREATE, ALTER, DROP).
Indexing: Implement indexing (e.g., B-trees) for fast data lookup.
Transaction Support: Enable transactions with ACID properties to ensure reliable state transitions.
Non-Functional Requirements (optional goals):
Performance: Efficient disk I/O and in-memory caching strategies.
Reliability: Robust error handling, recovery mechanisms, and data consistency checks.
Scalability: While the system is embedded, design choices should still allow the handling of increasing data volumes.
Resource Constraints: Operate with minimal memory footprint, a crucial factor for embedded applications.
Trade-offs and Constraints:
Complexity vs. Performance: Advanced optimizations might complicate the design, so balance is needed.
Extensibility vs. Simplicity: A modular architecture supports future enhancements without burdening the core system.
Consistency vs. Concurrency: Ensuring strong consistency might limit concurrent operations, so exploring techniques like MVCC becomes essential.
3. Architectural Overview
We will deep dive into understanding the architecture of databases like SQLite.
A database system has several major components, each handling specific tasks. This modular design keeps responsibilities clear and makes development and maintenance easier.
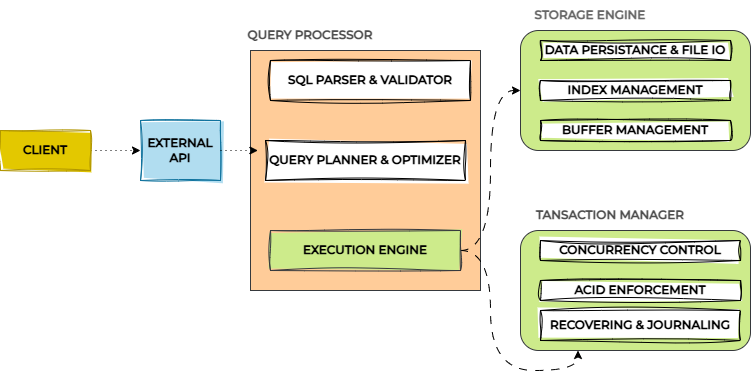
🗝️Key Components
Query Processor
SQL Parser and Validator: Converts SQL queries into a structured format and checks for errors.
Query Planner and Optimizer: Translates queries into efficient execution plans, deciding whether to use indexes or scan tables.
Execution Engine: Runs the execution plan, retrieving or modifying data. It can interpret queries or compile them into optimized code.
Storage Engine
Data Persistence: Stores data in files using fixed-size pages, managing disk access to keep data safe.
Index Management: Uses structures like B-trees for fast searching and sorting.
Page and Buffer Management: Controls how data is loaded into memory and written back to disk to reduce delays.
Transaction Manager
ACID Compliance: Ensures transactions are complete and reliable, preventing partial updates.
Concurrency Control: Manages multiple transactions at once using locks or multi-version techniques.
Recovery and Journaling: Logs changes to help restore data after crashes.
External API Interface
Client Interaction: Provides a simple API for applications to send queries, handle connections, and manage errors.
Data Flow
User Request Processing: An application sends an SQL query through the API.
Query Parsing and Planning: The system converts the query into a structured format and creates an execution plan.
Execution and Data Access: The engine follows the plan, retrieving or updating data through the storage engine.
Transaction Handling: If needed, the transaction manager ensures consistency and handles logging.
Response Delivery: The system sends results back to the application through the API.

Separation of Concerns:
Storage Layer: Abstracts disk I/O and data organization.
Execution Layer: Translates SQL commands into operations on the data.
Transaction Layer: Oversees atomicity and durability, isolating changes until commit time.
4. Storage Engine
4.1 Disk I/O and Page Management:
SQLite doesn’t mess around with random byte shuffling—it deals in pages.
Imagine chopping your database file into fixed-size chunks, say 4KB each, like pages in a book.
Every read or write grabs a whole page, which aligns beautifully with how disks operate (they hate jumping around).
The trick is minimizing those disk hits, and that’s where a page cache comes in.
A little in-memory stash of recently used pages.
when you need page 42, you check the cache first.
If it’s there, boom, no disk trip.
If not, you fetch it from the disk and tuck it into the cache for next time.
This is buffer management, keeping the hot stuff close, reducing latency, and letting the disk do its job.
SQLite’s cache is slick, often using an LRU (Least Recently Used) strategy to evict old pages when memory gets tight—something we’d want to mimic for scalability.
Pages and Blocks: Data is stored in fixed-size pages, which are the fundamental units of I/O. Designing an efficient page cache minimizes disk access.
Buffer Management: A caching layer in memory holds frequently accessed pages, reducing latency.
4.2 File Format and Persistence:
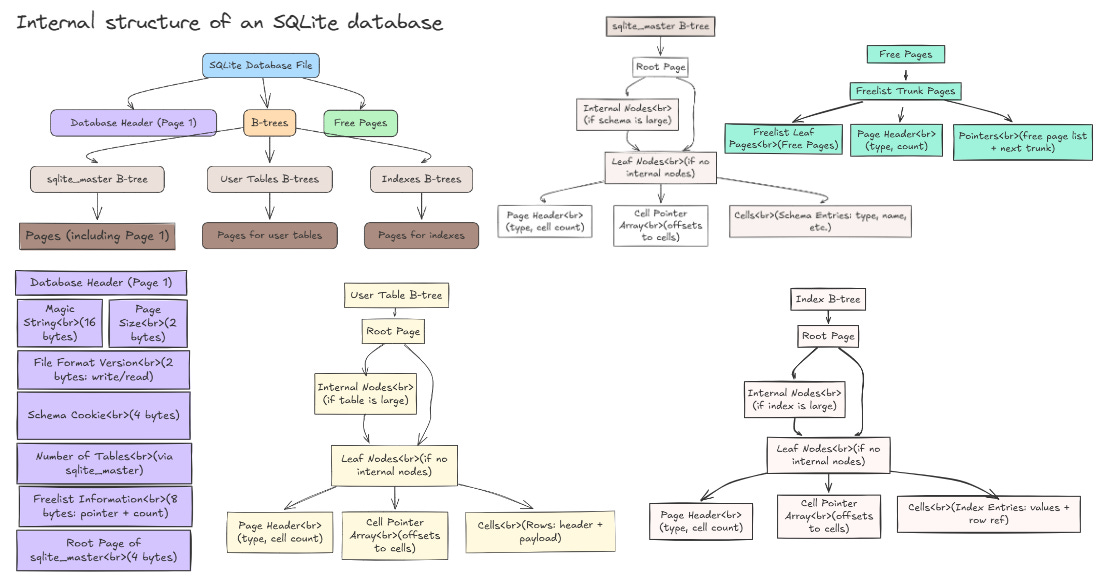
One of SQLite’s key features is building everything into a single file—data, indexes, metadata, the works.
Like a container, you can back up with a cp command.
We will follow same directions: reserve the first page as a header with a magic string (to say “yep, I’m a database”) and some metadata like the total page count.
After that, pages hold user data or structural info. The metadata might track which pages are free or allocated, kind of like a mini filesystem within the file. This single-file solve a problem of want to ship your DB to a friend? Just email the file.
Persistence means writing changes to disk reliably, and we’d lean on fsync calls to ensure nothing’s left in limbo if the power cuts out.
Single-File Database: Like SQLite, the entire database can reside in a single file. This simplifies backup, replication, and distribution.
Metadata: The file contains both user data and essential metadata, such as schema information and page allocation maps.
4.3 Data Structures for Index and Table Storage:

Enter the B-tree—a balanced tree that’s all about logarithmic-time lookups and range queries.
Based on the above example where each node holds multiple keys and pointers, keeping itself shallow even as data grows.
For a table, the B-tree’s leaves could store rows (or key-value pairs in our simpler case), sorted by key for fast searches.
I love how B-trees self-balance—insert a key, and if a node overflows, it splits, shuffling keys upward.
It’s elegant and keeps operations like “find all names between Alice and Bob” snappy.
SQLight uses B-trees heavily for indexes and tables, but there’s a sibling, the B+ tree, where only leaves hold data, and internal nodes are just signposts.
B+ trees shine for range scans since all values sit in a linked list at the bottom.
If we want to optimize certain queries. For now, a B-tree gives us the backbone we need.
B-Tree: A balanced tree structure is ideal for indexing. It allows logarithmic-time searches and efficient range queries.
Other Structures: Consider alternative data structures (e.g., B+ trees) for specific performance characteristics or query patterns.
5. Data Model and Schema Management
SQLite isn’t a free-for-all key-value dump—it’s relational, with tables, columns, and types.
5.1 Defining Tables, Columns, and Data Types
Think of a table as a grid: rows are records, columns are fields.
key-value setup is like a table with two columns: key and value.
To go relational, we’d define tables with named columns. Something like users with id (INTEGER) and name (TEXT).
SQLite supports types like INTEGER, TEXT, REAL, and BLOB, with a twist called type affinity: it’s flexible about what you shove in but nudges values toward the declared type.
We’d store this schema in our file’s metadata, so the DB knows its structure on startup.
Indexes, Views, and Triggers
Indexes boost lookups.
Imagine a query like “find all users named Alice” without an index, we’d scan every row.
A secondary B-tree on the name column lets us jump straight to the Alices.
We’d need to update these indexes whenever data changes, which adds overhead but pays off for frequent queries.
Views are virtual tables built up from queries like “show me all users over 30”
Offering abstraction without duplicating data.
Insert a row, and a trigger could auto-log it elsewhere.
Schema Evolution and Migrations
Schemas evolve—maybe we add an age column later.
SQLite handles this in place, tracking versions in its file header.
We could do the same like store a schema version and write logic to morph old data into the new layout during startup.
DDL (Data Definition Language) ops like ALTER TABLE need care—shift a column’s type, and you might need to rewrite every row. It’s a dance of preserving integrity while adapting, and SQLite nails it with minimal fuss.
6. SQL Parsing and Query Interpretation
6.1 Lexical Analysis and Tokenization
Raw SQL like SELECT name FROM users is just text until we tokenize it are split it into bits like SELECT (keyword), name (identifier), FROM (keyword), and users (identifier).
A tokenizer scans the string, catching errors early like a misplaced !—and hands off clean tokens.
6.2 Syntax Parsing and AST Generation
Next, we turn tokens into an Abstract Syntax Tree (AST) using a grammar.
It’s like a cooking recipe: “SELECT” means fetch data, followed by columns and a table.
The AST is a tree where SELECT is the root, with branches for names and users. SQLite’s grammar is a beast, but ours could start small—INSERT and SELECT only. The AST captures the structure and is ready for action.
Semantic Analysis and Validation
The syntax is half the battle do users table exist? Is the name a column?
Semantic checks catch these, ensuring the query makes sense in our DB’s world.
This step can also spot optimization tricks like using an index for WHERE name = 'Alice'.
It’s about understanding intent beyond raw grammar.

7. Query Execution Engine
7.1 Query Planning and Optimization
The AST becomes an execution plan with a guide like “scan table, filter rows.”
SQLite’s optimizer weighs options: full scan or index lookup?
It estimates costs on disk reads, and memory use—and picks the cheapest path. We’d start simple but could grow to consider stats like row counts.
7.2 Execution Strategies
SQLite uses a virtual machine (VM) to run plans, executing bytecode-like ops (fetch row, compare value).
Tweak the plan, and the VM adapts.
For speed, we could compile queries to native code, though that’s overkill for our toy. The VM approach keeps it scrappy and portable.
7.3 Handling Joins, Subqueries, and Aggregations
Joins (e.g., users JOIN orders) merge tables.
A nested loop join checks every pair which is slow but simple.
Hash joins or merge joins shine for bigger datasets.
Subqueries like SELECT * FROM users WHERE id IN (SELECT user_id FROM orders) can be inline or run separately, depending on correlation.
Aggregations (COUNT, SUM) need efficient loops over rows—tricky but doable with a B-tree’s sorted order.
8. Transaction Management and ACID Compliance
ACID is SQLite’s reliability badge.
8.1 ACID Properties
Atomicity means a transaction (e.g., transfer of money) fully succeeds or fails with no half-baked states.
Consistency keeps rules intact like foreign keys and constraints.
Isolation hides uncommitted changes from others.
Durability ensures committed data survives a crash. Our WAL helps with durability, but the rest needs work.
8.2 Concurrency Control
Locking is classic: write locks block others, read locks share.
Fine-grained locks (row-level) boost concurrency over coarse ones (table-level).
MVCC (Multi-Version Concurrency Control) is fancier with each transaction seeing a snapshot, avoiding locks.
SQLite does both and we could start with locks and dream of MVCC.
8.3 Transaction Isolation Levels
From loose (Read Uncommitted) to strict (Serializable), isolation levels trade consistency for speed.
Repeatable Read (SQLite’s default) balances well—reads are stable, and writes wait. We’d pick one and tune it.
9. Recovery and Journaling
9.1 Write-Ahead Logging (WAL) and Rollback Journals
WAL logs changes before touching the main file. SQLite’s rollback journal undoes partial writes; WAL skips that for speed. Both ensure recovery.
9.2 Crash Recovery Mechanisms
Checkpointing merges WAL into the main file periodically, keeping the log lean. On startup, we’d check integrity (header magic, page checksums) and replay the WAL if needed. It’s like hitting “undo” then “redo” after a spill.
9.3 Consistency Guarantees
Atomic writes via fsync lock data in place—power cuts won’t corrupt us. It’s slow but safe.
10. Query Optimizer
Query optimization is when the database gets smart and begins to work effectively. SQLite’s optimizer is magic at turning messy SQL into efficient plans, and we’re going to peek under its hood.
The big debate here is cost-based versus rule-based optimization.
Cost-based is the fancy approach and think of it as the optimizer playing detective with stats about your data, like how many rows are in a table or how values clump together.
It crunches numbers to guess how many disk reads or memory swaps a plan might need, then picks the cheapest one.
Rule-based, on the other hand, is more old-school, it’s got a playbook of heuristic tricks, like “always rewrite WHERE x = 5 AND y = 10 into something tighter.”
Cost-based feels smarter because it adapts to your data, but rule-based is simpler and predictable.
SQLite leans cost-based, and I’d nudge us that way too—it’s more future-proof as our DB grows.
Then there’s index selection and query rewriting.
Indexes are like cheat codes, say you’re hunting for “Alice” in a name column.
A B-tree index lets you zip straight there instead of slogging through every row.
The optimizer sniffs out which indexes shrink the search space and rewrites queries to use them, like turning WHERE name = 'Alice' into an index lookup.
Plan caching is the cherry on top
Why rethink a query you run 100 times a day?
Stash the plan and reuse it, skipping the optimization grind. SQLite does this, and it’s a no-brainer for us too.
Execution plan analysis is the dev-friendly bit.
Ever wonder what the optimizer’s up to?
EXPLAIN plans spill the beans like “scan this index, filter that.”
It’s a debugger’s dream, letting you tweak queries or indexes when things go wonky. We’d want this to keep our sanity.
11. Concurrency and Multi-threading
Concurrency is interesting where multiple users hit the DB at once, and we have to keep it smooth.
SQLite handles this with finesse, and we’re taking notes.
Managing concurrent access is all about locks.
Coarse-grained locks on the whole table are simple but stingy with concurrency.
Fine-grained locks zoom in to rows, letting more folks poke around at once.
SQLite mixes both, and I’d lean fine-grained for scalability
Then there’s optimistic versus pessimistic concurrency.
Optimistic bets conflicts are rare let everyone work, and check for clashes at commit time. Pessimistic locks stuff down upfront. SQLite’s usually pessimistic, but optimistic is tempting for high-read setups.
Deadlocks are the nightmare as well
Two transactions stuck, each waiting for the other. Detection means watching for cycles in a “who’s waiting for who” graph; spot one, and you’ve got a deadlock.
Pick a transaction and kill it to break the loop.
SQLite’s got this wired, and we’d need something similar to avoid eternal standoffs.
Thread pooling hands queries to a squad of worker threads, keeping the CPU busy without chaos.
Lock-free data structures are the tough option, fancy concurrent tricks that dodge locks entirely, though they’re a brain-bender to get right.
SQLite sticks to locks, but I would daydream about lock-free for a high-traffic twist.
12. API Design and External Interfaces
A database isn’t much without a clean way in. SQLite’s C API is a legend
Simple, consistent, and embeddable anywhere.
it’s just a handful of functions like sqlite3_open(), sqlite3_exec(), and sqlite3_prepare(), but they give you everything you need to manage a database without the bloat of bigger systems.
Think sqlite3_open vibes, where you pass a filename and get a handle, with no fuss. Good docs, sane naming, and clear error codes make it a joy to use.
Bindings for other languages widen the net—Python, Java, whatever. Wrappers keep the API’s soul intact across tongues, so db.query() feels the same everywhere. Embedding’s the killer app—SQLite shines in apps, not servers, so we’d spell out how to initialize, configure, and shut down cleanly.
Extensibility’s the fun part. Virtual tables let you plug external data—like a CSV file—into SQL as if it’s native. User-defined functions (UDFs) are the spice—write my_cool_func() in SQL, and it runs your code. SQLite’s got both, and they’d make our DB a playground.
13. Performance Tuning and Benchmarking
Performance is where you separate the toys from the tools. SQLite’s lean and mean, and we’re chasing that.
Caching’s king—stash hot pages in memory to dodge disk I/O. Pre-allocate memory chunks or use custom allocators to keep things tight—SQLite’s obsessive here. I/O optimization means leaning into sequential reads over random hops; disks hate seek time, and we’d tune for that. Profiling tools sniff out bottlenecks—where’s the query engine choking?—and we’d lean on them hard.
Benchmarking is the reality check. Synthetic tests (bulk inserts, gnarly joins) show what we can handle, but real-world workloads—think app traffic—prove it. SQLite’s battle-tested this way, and we’d follow to keep our claims honest.
14. Security and Data Integrity
Security’s non-negotiable—data’s precious. SQLite’s light on built-in access control, trusting the app layer, but we’d sketch some basics: roles and permissions to gate who does what. SQL injection’s the boogeyman—our parser better scrub inputs like a pro, or we’re toast.
Encryption keeps data safe—at rest, encrypt the file so a stolen disk’s useless; in transit, TLS if we ever go networked. SQLite offers this as an add-on, and we’d want it too. Corruption’s the silent killer—checksum pages to catch bit rot, and maybe replicate data for critical stuff. SQLite’s paranoid about this, and I’m sold.
Building the SQLight in Go
SQLight is a relational database that stores data in tables, supports SQL-like queries, and keeps everything in a single file. For our mini version, we’ll aim for simplicity: a single-table database that stores key-value pairs (think of it as a table with two columns: key and value). We’ll persist it to disk, support basic operations like INSERT and SELECT, and handle some light concurrency. No fancy B-trees or SQL parsing yet—just the essentials to grok the fundamentals.
NOTE: This is a initial version when I started building so some code might be different from the GitHub version (also some new features).
Introduction and Setting up the REPL
The REPL (Read-Eval-Print Loop) provides an interactive interface for users to input commands and see results, essential for testing. In Go, we use standard input/output for this, as shown below:

package main
import (
"bufio"
"io"
"os"
)
func main() {
reader := bufio.NewReader(os.Stdin)
for {
os.Stdout.Write([]byte("db> "))
input, err := reader.ReadString('\n')
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
os.Stdout.Write([]byte(input))
}
}This basic REPL reads user input and echoes it, setting the stage for processing SQL commands later.
SQL Compiler
SQL queries need parsing and execution. We define an abstract syntax tree (AST) for statements and a virtual machine to execute them. Here's a simplified implementation:
type Statement interface {
Exec(db *Database) error
}
type SelectStatement struct {
Table string
}
func (s *SelectStatement) Exec(db *Database) error {
return nil
}
type InsertStatement struct {
Table string
Values []interface{}
}
func (s *InsertStatement) Exec(db *Database) error {
return nil
}
type CreateStatement struct {
Table string
Columns []string
}
func (s *CreateStatement) Exec(db *Database) error {
return nil
}
func ParseSQL(sql string) (Statement, error) {
return nil, nil
}
type Database struct {}
func (db *Database) Execute(sql string) error {
stmt, err := ParseSQL(sql)
if err != nil {
return err
}
return stmt.Exec(db)
}This setup handles basic parsing, with plans to expand for more complex queries, referencing resources like simple SQL parser in Go for inspiration.
An In-Memory, Append-Only, Single-Table Database
Start with a simple in-memory database, using a map for tables and slices for records, focusing on append-only operations:
type Record struct {
Id int
Name string
}
type Table struct {
records []*Record
}
func (t *Table) Insert(r *Record) {
t.records = append(t.records, r)
}
func (t *Table) Select() []*Record {
return t.records
}
type Database struct {
tables map[string]*Table
}
func NewDatabase() *Database {
return &Database{tables: make(map[string]*Table)}
}
func (db *Database) CreateTable(name string) error {
db.tables[name] = &Table{}
return nil
}
func (db *Database) InsertIntoTable(name string, r *Record) error {
if table, ok := db.tables[name]; ok {
table.Insert(r)
return nil
}
return fmt.Errorf("Table %s not found", name)
}
func (db *Database) SelectFromTable(name string) ([]*Record, error) {
if table, ok := db.tables[name]; ok {
return table.Select(), nil
}
return nil, fmt.Errorf("Table %s not found", name)
}This implementation is basic, supporting creation, insertion, and selection, with plans to enhance for more complex operations, aligning with Implementing a B-Tree in Go.
Our First Tests (and Bugs)
Testing ensures functionality. Use Go's testing package to verify operations, expecting to find and fix bugs:
go
func TestDatabase(t *testing.T) {
db := NewDatabase()
err := db.CreateTable("users")
if err != nil {
t.Fatalf("Error creating table: %v", err)
}
r1 := &Record{Id: 1, Name: "Alice"}
r2 := &Record{Id: 2, Name: "Bob"}
err = db.InsertIntoTable("users", r1)
if err != nil {
t.Fatalf("Error inserting record: %v", err)
}
err = db.InsertIntoTable("users", r2)
if err != nil {
t.Fatalf("Error inserting record: %v", err)
}
records, err := db.SelectFromTable("users")
if err != nil {
t.Fatalf("Error selecting from table: %v", err)
}
if len(records) != 2 {
t.Fatalf("Expected 2 records, got %d", len(records))
}
}This test case checks table creation, insertion, and selection, identifying any issues early, consistent with modern testing practices in Go.
Persistence to Disk
To persist data, save and load the database using JSON, ensuring data recovery across sessions:
import (
"bytes"
"encoding/json"
"io/ioutil"
)
func (db *Database) SaveToFile(filename string) error {
buf := new(bytes.Buffer)
enc := json.NewEncoder(buf)
enc.SetIndent("", " ")
if err := enc.Encode(db.tables); err != nil {
return err
}
return ioutil.WriteFile(filename, buf.Bytes(), 0644)
}
func LoadDatabaseFromFile(filename string) (*Database, error) {
db := NewDatabase()
b, err := ioutil.ReadFile(filename)
if err != nil {
return nil, err
}
if err := json.NewDecoder(bytes.NewReader(b)).Decode(&db.tables); err != nil {
return nil, err
}
return db, nil
}This basic persistence uses JSON for simplicity, with plans to optimize for performance later using B+ Trees.
The Cursor Abstraction
Cursors enable record navigation, crucial for query execution. Implement a simple cursor for our in-memory table:
type Cursor struct {
table *Table
current int
}
func (t *Table) NewCursor() *Cursor {
return &Cursor{table: t, current: -1}
}
func (c *Cursor) Next() *Record {
c.current++
if c.current < len(c.table.records) {
return c.table.records[c.current]
}
return nil
}
func (c *Cursor) Reset() {
c.current = -1
}This cursor allows iterating through records, supporting operations like SELECT with multiple rows.
B+ Tree implementations
For efficient storage, especially on disk, use B+ Trees (noting SQLite's use, correcting from user's "B-Tree"). Implement a basic in-memory B+ Tree:
type BTreeNode struct {
keys []int
children []*BTreeNode
records []*Record
leaf bool
next *BTreeNode // For leaf nodes to link to the next leaf
}
func (n *BTreeNode) IsFull(t int) bool {
return len(n.keys) == 2*t - 1
}
func (n *BTreeNode) InsertNonFull(k int, r *Record) {
// Implementation to insert a key and record into the node
}
func (n *BTreeNode) SplitChild(i int, t int) {
// Implementation to split a child node
}B+ Trees, with data only in leaf nodes, are ideal for disk-based databases.
B+ Tree Leaf Node Format
Define how leaf nodes store data, crucial for efficient retrieval:
type BTreeNode struct {
keys []int
children []*BTreeNode
records []*Record
leaf bool
next *BTreeNode // For leaf nodes to link to the next leaf
}
func (n *BTreeNode) InsertRecord(k int, r *Record) {
// Implementation to insert a record into the leaf node
}Leaf nodes hold records, sorted by keys, with internal nodes for navigation, optimizing disk I/O.
Binary Search and Duplicate Keys
Implement binary search for efficiency and handle duplicate keys, essential for real-world databases:
func (n *BTreeNode) Find(k int) int {
// Implementation of binary search to find the index of key k
}
func (n *BTreeNode) Insert(k int, r *Record) {
// Insert key and record, handling duplicates
}Binary search speeds up key lookups, and handling duplicates ensures data integrity.
Splitting a Leaf Node
When full, split leaf nodes to maintain balance, ensuring performance:
func (n *BTreeNode) SplitLeaf(t int) (*BTreeNode, int) {
// Implementation to split the leaf node
}Splitting redistributes keys and records, maintaining B+ Tree properties, crucial for scalability.
Recursively Searching the B+ Tree
Implement recursive search to find records, traversing from root to leaf:
func (root *BTreeNode) Search(k int) *Record {
// Implementation to search for a key in the B+ Tree
}Recursive search ensures efficient key lookup, leveraging the tree's structure for logarithmic time complexity.
Scanning a Multi-Level B+ Tree
Enable scanning for full table scans, supporting queries like SELECT *:
func (root *BTreeNode) Scan() []*Record {
// Implementation to scan all records
}Scanning iterates through leaf nodes in order, which is essential for range queries.
Updating Parent Node After a Split
After splitting, update parent nodes to reflect the new structure:
func (root *BTreeNode) Insert(k int, r *Record) {
// Implementation to insert a key and record, handling splits and updating parents
}This maintains tree integrity, ensuring correct navigation post-split, critical for dynamic updates.
Splitting Internal Nodes
Handle internal node splits, similar to leaf nodes, for tree balance:
func (n *BTreeNode) SplitInternal(i int, t int) {
// Implementation to split an internal node
}Internal splits ensure the tree remains balanced, supporting large datasets efficiently.
The B+ Tree implementation integrates it into the database with insertion, search, and scanning capabilities. The project now supports basic SQL commands, persists to disk, and uses an efficient storage structure akin to SQLite. Future steps (Part 15) suggest enhancing functionality, making this a solid foundation for a full-featured database.
That’s it for the day
While this is the simplest and initial version you can learn there is more on Github repo and also feel free to contribute new features.
Liked this article? Make sure to ❤️ click the like button.
Feedback or addition? Make sure to 💬 comment.
Know someone who would find this helpful? Make sure to 🔁 share this post.
Your support means a great deal! Thank you! lets learn together!
Hey i made the similar in go. https://github.com/darshan117/BroSql