
Lets build Git from scratch
Lets build a git from scratch called Opengit in go

In this series, I am trying to build commonly used services from scratch (a lighter version of it, but we will try to cover it in depth). If you are new to our newsletter feel free to reach archive here
This post is an attempt at explaining the Git version control system from the bottom up, that is, starting at the most fundamental level and moving up from there.
This does not sound too easy and has been attempted multiple times with questionable success.
Git’s true power lies under the hood. To understand it fully, we’re going to do something ambitious: rebuild a lightweight version of Git from scratch.
(Btw, if the code formatting bugs you, please refer to the GitHub repo for the full version)
🥳🥳You can see the complete code here in this github repo and demo below.
PS: If you would like to contribute to the repo, you are always welcome.
Let’s start!
What Is Git, Really?
We all have seen Google Docs.
You write something, edit it, and if you mess up, you can check "Version History" to restore an older version. Git does the same for code but with more advanced features like branching and merging.
But unlike Google Docs, where changes are saved automatically, Git requires you to manually save (commit) your work and describe what has changed. Developers can also work on different versions (branches) of a project at the same time and later combine them.
This is the world of Git, a tool so ubiquitous among developers that it’s practically a reflex: git add, git commit, git push.
But beneath these commands lies a simple system of clarity and originality.
We are not going to see every Git command (there are over 150, and we’d be here all day). Instead, I want to show you the beating heart of Git: its objects, its references, and its staging area.
By the end, you’ll see Git not as a black box but as a well-crafted machine.
So, where does all this Git magic happen?
In a repository, of course! Think of it as the home base for your project. Pretty much every time you type a Git command, you’re looking at a repository.
Repository
Almost every time we run a git command, we’re trying to do something to a repository: create it, read from it, or modify it.
It consists of two main parts:
The Work Tree: This is where your project’s files live, meaning the ones you edit and modify.
The Git Directory: This hidden directory (
.git/) stores all Git’s internal data, including commits, branches, and metadata.
Git’s Object Database
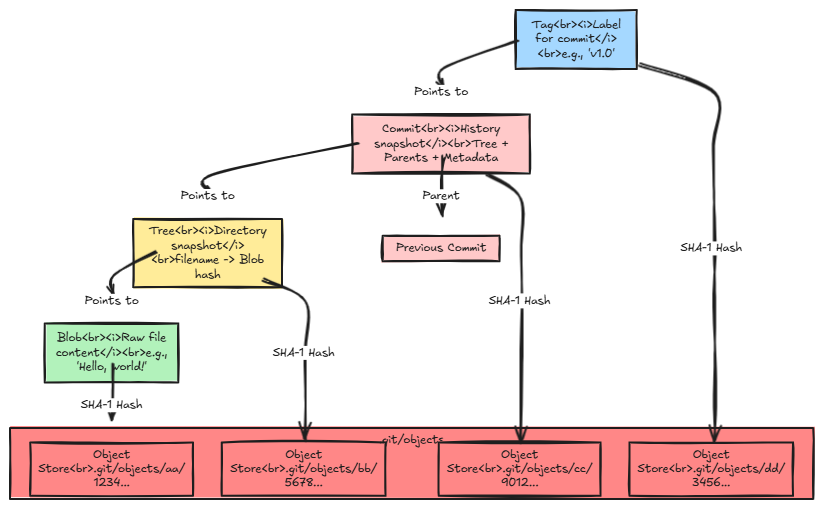
Git is a content-addressable storage system.
That’s a different way of saying it stores stuff like files, directories, and entire histories by giving each piece a unique name based on what it is. Like a magical library where every book’s title is a fingerprint of its contents.
Change one word, and the fingerprint changes, too.
These “fingerprints” are SHA-1 hashes—40-character strings like d670460b4b4aece5915caf5c68d12f560a9fe3e4.
What is a hash function?
SHA-1 is what we call a “hash function”. Simply put, a hash function is a kind of unidirectional mathematical function: it is easy to compute the hash of a value, but there’s no way to compute back which value produced a hash.
A very simple example of a hash function is the classical
len(orstrlen) function, which returns the length of a string. It’s really easy to compute the length of a string, and the length of a given string will never change (unless the string itself changes, of course!) but it’s impossible to retrieve the original string, given only its length. Cryptographic hash functions are a much more complex version of the same, with the added property that computing an input meant to produce a given hash is hard enough to be practically impossible. (To produce an inputiwithstrlen(i) == 12, you just type twelve random characters. With algorithms such as SHA-1. it would take much, much longer — long enough to be practically impossible1).
Git computes them using the SHA-1 algorithm, which takes some data, scrambles it cleverly, and spits out a practically unique hash. The odds of two different pieces of data having the same hash are so tiny that we’ll pretend they don’t exist.
Git organizes everything into four types of objects, each stored in the .git/objects directory. Let’s meet them:
Blobs: These are your files, pure and simple. Take a text file with “Hello, world!” inside. Git wraps it with a tiny header like “blob 13\x00” (13 is the length) and computes its hash. That hash becomes its address. If you edit the file to “Hello, Git!”, it gets a new hash. Blobs don’t care about filenames; they’re just raw content.
Trees: Imagine a snapshot of your project’s directory. A tree object is like a table of contents, listing filenames, their permissions (e.g., “100644” for a regular file), and the hashes of their blobs or sub-trees. Trees connect blobs into a structure.
Commits: Here’s where the magic happens. A commit object ties everything together: it points to a tree (the project’s state), lists parent commits (the history), and adds metadata like “Author: XXX YYY” and a timestamp. It’s a checkpoint in your story, saying, “This is what the world looked like then.”
Tags: These are optional labels, often used to mark releases like “v1.0”. A lightweight tag is just a pointer to a commit, while an annotated tag is its own object with extra info (like a message). They’re like sticky notes on your timeline.
You write a file, readme.txt.
Git turns it into a blob, hashes it, and stores it in .git/objects (d670460b....).
The hash’s first two characters (say, d6) become a subdirectory, and the rest (70460b...) the filename.
Why split it?
To keep the directory manageable, millions of files would pile up in one place.
Now, these objects are compressed with zlib to save space.
When Git needs them, it unzips and reads them back. This object store is Git’s memory: immutable, efficient, and content-driven.
Before we understand the object storage system, we must understand their exact storage format. An object starts with a header that specifies its type:
blob,commit,tagortree(more on that in a second). This header is followed by an ASCII space (0x20), then the size of the object in bytes as an ASCII number, then null (0x00) (the null byte), then the contents of the object. The first 48 bytes of a commit object in Wyag’s repo look like this:
00000000 63 6f 6d 6d 69 74 20 31 30 38 36 00 74 72 65 65 |commit 1086.tree|
00000010 20 32 39 66 66 31 36 63 39 63 31 34 65 32 36 35 | 29ff16c9c14e265|
00000020 32 62 32 32 66 38 62 37 38 62 62 30 38 61 35 61 |2b22f8b78bb08a5a|
In the first line, we see the type header, a space (
0x20), the size in ASCII (1086) and the null separator0x00. The last four bytes on the first line are the beginning of that object’s contents, the word “tree” — we’ll discuss that further when we’ll talk about commits.
References
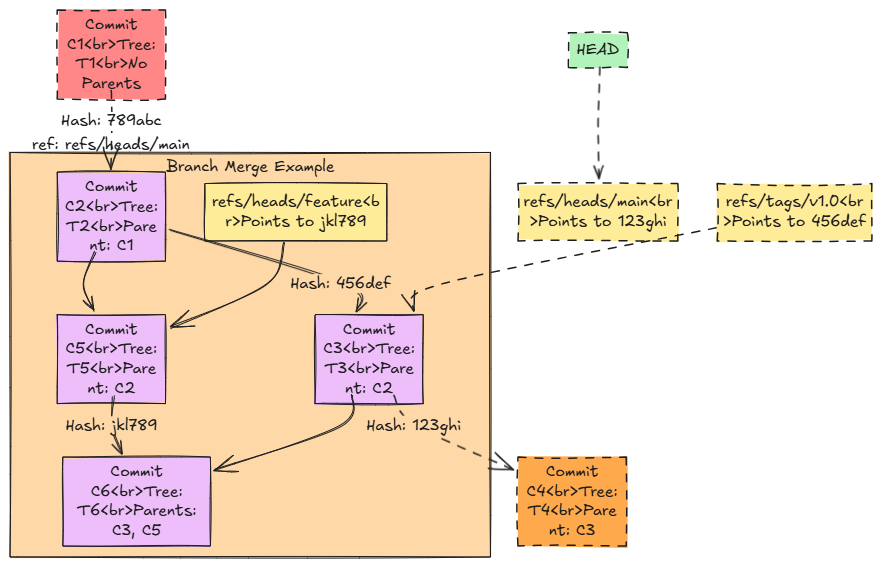
Objects alone are static, meaning they’re just data with hashes.
How does Git know where you are in your project?
Enter references, or refs. They are like bookmarks pointing to specific commits.
The most famous ref is HEAD.
Open .git/HEAD, and you might see something like ref: refs/heads/main.
This means HEAD points to the main branch. Peek at .git/refs/heads/main, and you’ll find a commit hash which says, d670460b.... That’s your current position in history.
Refs come in flavors:
Branches (e.g., refs/heads/main): Movable pointers. When you commit, main slides forward to the new commit hash.
Tags (e.g., refs/tags/v1.0): Fixed pointers, marking milestones.
HEAD: A special ref that tracks where you’re working—usually a branch, but it can point directly to a commit (a “detached HEAD” state).
Here’s the beauty: commits form a graph. Each commit points to its parents, creating a chain—or a tree if you’ve merged branches. Refs are how you navigate this graph. Want to see your history? Git starts at HEAD, follows the parent links, and voilà—your git log.
The Index

Now, let’s talk about the index (.git/index), Git’s staging area.
It’s the middle ground between your working directory (the files you see) and the object database.
Imagine it as a draft of your next commit.
When you git add readme.txt, Git:
Reads the file.
Creates a blob and stores it.
Updates the index with the file’s path, hash, and metadata (like mode and timestamp).
The index isn’t a full tree yet—it’s a flat list of files you’ve staged. Run git commit, and Git turns this list into a tree object, links it to a commit, and updates your branch ref. It’s like rehearsing a scene before recording it.
Why have an index? Flexibility. You can stage some changes, leave others unstaged, and craft your commits deliberately. It’s Git’s way of saying, “Take your time—tell me exactly what to save.”
Overall, how index works?
When you commit, what git actually does is turn the index file into a new tree object. To summarize:→ When the repository is “clean”, the index file holds the exact same contents as the HEAD commit, plus metadata about the corresponding filesystem entries. For instance, it may contain something like:
lets consider this example
There’s a file calledtestwhose contents are blob 797441c76e59e28794458b39b0f1eff4c85f4fa0. The realtestfile, in the worktree, was created on 2025-03-15 15:28:29.168572151, and last modified 2025-03-15 15:28:29.1689427709. It is stored on device 65026, inode 8922881.→ When you
git addorgit rm, the index file is modified accordingly. In the example above, if you modifytest, andaddyour changes, the index file will be updated with a new blob ID (the blob itself will also be created in the process, of course), and the various file metadata will be updated as well sogit statusknows when not to compare file contents.→ When you
git committhose changes, a new tree is produced from the index file, a new commit object is generated with that tree, branches are updated and we’re done.

Putting It Together
Let’s walk through a story to see how these pieces fit.
You Start Fresh:
git init: Creates .git with empty objects, refs, and HEAD pointing to refs/heads/main (which doesn’t exist yet).
Your working directory is empty.
You Add a File:
Write “Hello” in greeting.txt.
git add greeting.txt: Git hashes the content (“blob 6\x00Hello”), stores it as, say, a1b2c3..., and updates the index with greeting.txt -> a1b2c3....
You Commit:
git commit -m "Add greeting": Git builds a tree (greeting.txt -> a1b2c3...), hashes it (e.g., d4e5f6...), and creates a commit with tree d4e5f6..., no parents, and your message. The commit’s hash (say, 789abc...) goes into refs/heads/main, and HEAD follows along.
You Edit and Commit Again:
Change greeting.txt to “Hello, Git!”.
git add greeting.txt: New blob (0def12...), index updated.
git commit -m "Update greeting": New tree (g1h2i3...), new commit (456def...) with parent 789abc.... main moves to 456def....
You Look Back:
git log: Git follows HEAD -> 456def -> 789abc, showing your history.
git cat-file -p 456def: Reveals the commit’s tree, parent, and message.
Your project’s evolution is now a chain of commits, each a snapshot preserved by trees and blobs, navigated by refs, and staged via the index.
Why It Works
Git’s design is deceptively simple, yet it solves complex problems:
Immutability: Objects never change. Edit a file, and you get a new blob. This makes history reliable.
Efficiency: Hashes let Git deduplicate identical content: two files with the same text share one blob.
Flexibility: The graph of commits, paired with refs, lets you branch, merge, and rewind time.
It’s like a Lego set: small, consistent pieces (blobs, trees, commits) snap together into something vast.
We’ve skipped the full command list, but here’s how some tie in:
git add: Updates the index with new blobs.
git commit: Turns the index into a tree and commit, moves the branch.
git log: Traverses the commit graph from HEAD.
git checkout: Swaps your working directory and HEAD to match a commit’s tree.
Each command is a tool to manipulate this system like objects, refs, index—in precise ways.
Let’s do some coding now
You know the drill we cover only a minimal version here (the Complete version would be available in GitHub)
Below is a minimal tutorial to build a simplified version of Git from scratch in Go, focusing on the key concepts: objects (blobs, trees, commits), refs, and the index.
This isn’t a full Git implementation (we’ll skip advanced features like tags, branching, or compression), but it captures the essence of how Git works → enough to initialize a repo, stage files, commit changes, and view history.
We’ll implement four commands: init, add, commit, and log. The code is minimal, with explanations to guide you through Git’s internals.
Building OpenGit from Scratch
By the end, you’ll have a working tool that mimics Git’s heart: objects, refs, and the index. Let’s dive in!
Step 1: Setup and Project Structure
Create a directory called Opengit and set up this structure:
Opengit/
├── main.go # Command-line entry point
├── repo.go # Repository handling
├── objects.go # Blob, Tree, Commit objects
├── index.go # Staging area
├── refs.go # References (HEAD, branches)Initialize a Go module:
cd Opengit
go mod init OpengitStep 2: Core Concepts and Code
Repository (repo.go)
This defines the .git directory and basic file helpers.
package main
import (
"os"
"path/filepath"
)
type Repository struct {
Worktree string // Current directory
Gitdir string // .git directory
}
func NewRepository(path string) (*Repository, error) {
worktree, err := filepath.Abs(path)
if err != nil {
return nil, err
}
return &Repository{
Worktree: worktree,
Gitdir: filepath.Join(worktree, ".git"),
}, nil
}
func (r *Repository) GitFile(path ...string) string {
return filepath.Join(r.Gitdir, filepath.Join(path...))
}Git’s repository is just a .git folder holding objects, refs, and the index.
Objects (objects.go)
Git stores everything as objects: blobs (files), trees (directories), and commits (history).
package main
import (
"crypto/sha1"
"fmt"
"strings"
"time"
)
type Blob struct {
Data []byte
}
func NewBlob(data []byte) *Blob {
return &Blob{Data: data}
}
func (b *Blob) Serialize() []byte {
return append([]byte(fmt.Sprintf("blob %d\x00", len(b.Data))), b.Data...)
}
func (b *Blob) Hash() string {
data := b.Serialize()
hash := sha1.Sum(data)
return fmt.Sprintf("%x", hash)
}
type TreeEntry struct {
Name string
Hash string
}
type Tree struct {
Entries []TreeEntry
}
func NewTree(entries []TreeEntry) *Tree {
return &Tree{Entries: entries}
}
func (t *Tree) Serialize() []byte {
var buf strings.Builder
for _, e := range t.Entries {
fmt.Fprintf(&buf, "100644 %s\x00%s", e.Name, e.Hash)
}
return append([]byte(fmt.Sprintf("tree %d\x00", buf.Len())), buf.String()...)
}
func (t *Tree) Hash() string {
data := t.Serialize()
hash := sha1.Sum(data)
return fmt.Sprintf("%x", hash)
}
type Commit struct {
Tree string
Parent string // Single parent for simplicity
Author string
Time time.Time
Msg string
}
func NewCommit(tree, parent, msg string) *Commit {
return &Commit{
Tree: tree,
Parent: parent,
Author: "User <user@example.com>",
Time: time.Now(),
Msg: msg,
}
}
func (c *Commit) Serialize() []byte {
var buf strings.Builder
fmt.Fprintf(&buf, "tree %s\n", c.Tree)
if c.Parent != "" {
fmt.Fprintf(&buf, "parent %s\n", c.Parent)
}
fmt.Fprintf(&buf, "author %s %d +0000\n", c.Author, c.Time.Unix())
fmt.Fprintf(&buf, "\n%s\n", c.Msg)
return append([]byte(fmt.Sprintf("commit %d\x00", buf.Len())), buf.String()...)
}
func (c *Commit) Hash() string {
data := c.Serialize()
hash := sha1.Sum(data)
return fmt.Sprintf("%x", hash)
}Objects are content-addressed (hashed with SHA-1) and immutable. Blobs hold file data, trees organize files, and commits link snapshots to history.
Index (index.go)
The index stages change before committing.
package main
import (
"fmt"
"os"
)
type Index struct {
Entries map[string]string // Path -> Blob hash
}
func ReadIndex(r *Repository) (*Index, error) {
data, err := os.ReadFile(r.GitFile("index"))
if err != nil {
if os.IsNotExist(err) {
return &Index{Entries: make(map[string]string)}, nil
}
return nil, err
}
idx := &Index{Entries: make(map[string]string)}
lines := strings.Split(string(data), "\n")
for _, line := range lines {
if line == "" {
continue
}
parts := strings.Split(line, " ")
idx.Entries[parts[0]] = parts[1]
}
return idx, nil
}
func WriteIndex(r *Repository, idx *Index) error {
var buf strings.Builder
for path, hash := range idx.Entries {
fmt.Fprintf(&buf, "%s %s\n", path, hash)
}
return os.WriteFile(r.GitFile("index"), []byte(buf.String()), 0644)
}The index is a staging area→ a list of files and their blob hashes ready for the next commit.
Refs (refs.go)
Refs point to commits, like HEAD and branches.
package main
import (
"os"
"path/filepath"
"strings"
)
type Refs struct {
r *Repository
}
func NewRefs(r *Repository) *Refs {
return &Refs{r: r}
}
func (refs *Refs) ReadHEAD() (string, error) {
data, err := os.ReadFile(refs.r.GitFile("HEAD"))
if err != nil {
return "", err
}
ref := strings.TrimSpace(string(data))
if strings.HasPrefix(ref, "ref: ") {
return refs.ReadRef(strings.TrimPrefix(ref, "ref: "))
}
return ref, nil
}
func (refs *Refs) WriteHEAD(value string) error {
return os.WriteFile(refs.r.GitFile("HEAD"), []byte(value+"\n"), 0644)
}
func (refs *Refs) ReadRef(ref string) (string, error) {
data, err := os.ReadFile(refs.r.GitFile(ref))
if err != nil {
if os.IsNotExist(err) {
return "", nil
}
return "", err
}
return strings.TrimSpace(string(data)), nil
}
func (refs *Refs) WriteRef(ref, value string) error {
path := refs.r.GitFile(ref)
os.MkdirAll(filepath.Dir(path), 0755)
return os.WriteFile(path, []byte(value+"\n"), 0644)
}Refs are pointers to commits. HEAD tracks your current position, often via a branch like main.
Main and Commands (main.go)
Tie it with a CLI and implement init, add, commit, and log.
package main
import (
"fmt"
"os"
"path/filepath"
"strings"
)
func main() {
if len(os.Args) < 2 {
fmt.Println("Usage: minigit <command> [<args>]")
os.Exit(1)
}
cmd := os.Args[1]
args := os.Args[2:]
r, err := NewRepository(".")
if err != nil {
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
os.Exit(1)
}
switch cmd {
case "init":
initRepo(r)
case "add":
addFiles(r, args)
case "commit":
commitChanges(r, args)
case "log":
showLog(r)
default:
fmt.Printf("Unknown command: %s\n", cmd)
os.Exit(1)
}
}
func initRepo(r *Repository) {
os.MkdirAll(r.GitFile("objects"), 0755)
os.MkdirAll(r.GitFile("refs/heads"), 0755)
r.WriteRef("HEAD", "ref: refs/heads/main")
fmt.Println("Initialized empty Git repository")
}
func addFiles(r *Repository, files []string) {
idx, err := ReadIndex(r)
if err != nil {
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
os.Exit(1)
}
for _, file := range files {
data, err := os.ReadFile(file)
if err != nil {
fmt.Fprintf(os.Stderr, "Error reading %s: %v\n", file, err)
continue
}
blob := NewBlob(data)
hash := blob.Hash()
os.MkdirAll(r.GitFile("objects", hash[:2]), 0755)
os.WriteFile(r.GitFile("objects", hash[:2], hash[2:]), blob.Serialize(), 0644)
idx.Entries[file] = hash
}
WriteIndex(r, idx)
}
func commitChanges(r *Repository, args []string) {
idx, err := ReadIndex(r)
if err != nil {
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
os.Exit(1)
}
if len(idx.Entries) == 0 {
fmt.Println("Nothing to commit")
os.Exit(1)
}
entries := make([]TreeEntry, 0, len(idx.Entries))
for path, hash := range idx.Entries {
entries = append(entries, TreeEntry{Name: path, Hash: hash})
}
tree := NewTree(entries)
treeHash := tree.Hash()
os.MkdirAll(r.GitFile("objects", treeHash[:2]), 0755)
os.WriteFile(r.GitFile("objects", treeHash[:2], treeHash[2:]), tree.Serialize(), 0644)
refs := NewRefs(r)
parent, _ := refs.ReadHEAD()
msg := "Initial commit"
if len(args) > 0 {
msg = args[0]
}
commit := NewCommit(treeHash, parent, msg)
commitHash := commit.Hash()
os.MkdirAll(r.GitFile("objects", commitHash[:2]), 0755)
os.WriteFile(r.GitFile("objects", commitHash[:2], commitHash[2:]), commit.Serialize(), 0644)
refs.WriteRef("refs/heads/main", commitHash)
refs.WriteHEAD("ref: refs/heads/main")
fmt.Printf("Committed: %s\n", commitHash)
}
func showLog(r *Repository) {
refs := NewRefs(r)
hash, err := refs.ReadHEAD()
if err != nil || hash == "" {
fmt.Println("No commits yet")
return
}
for hash != "" {
data, err := os.ReadFile(r.GitFile("objects", hash[:2], hash[2:]))
if err != nil {
fmt.Fprintf(os.Stderr, "Error: %v\n", err)
return
}
lines := strings.Split(string(data), "\n")
tree, parent, author, msg := "", "", "", ""
for i, line := range lines {
if strings.HasPrefix(line, "tree") {
tree = strings.Fields(line)[1]
} else if strings.HasPrefix(line, "parent") {
parent = strings.Fields(line)[1]
} else if strings.HasPrefix(line, "author") {
author = line[7:]
} else if line == "" && i+1 < len(lines) {
msg = strings.Join(lines[i+1:], "\n")
}
}
fmt.Printf("commit %s\nAuthor: %s\n\n %s\n\n", hash, author, msg)
hash = parent
}
}Step 3: Test It Out
Build and run your minimal Git:
go build -o OpengitInitialize:
./Opengit initCreates .git with objects and refs.
Add a File:
echo "Hello, Git!" > hello.txt
./Opengit add hello.txtStages hello.txt in the index and stores its blob.
Commit:
./Opengit commit "Add hello.txt"Creates a tree and commit, updates main.
View History:
./Opengit logShows the commit with its message and author.
Edit and Commit Again:
echo "Hello again!" > hello.txt
./Opengit add hello.txt
./Opengit commit "Update hello.txt"
./Opengit logAdds a new commit, links it to the previous one.
Key Concepts
Objects:
Blob: Stores hello.txt’s content, hashed as its ID.
Tree: Lists files (just hello.txt here) and their blob hashes.
Commit: Ties a tree to a parent commit (or none for the first), with metadata.
Refs:
HEAD points to refs/heads/main, which points to the latest commit hash.
Each commit moves the main forward.
Index:
A simple list of staged files and their blob hashes are written to .git/index.
add updates it; commit turns it into a tree.
What’s Missing?
This is bare-bones Git:
No compression (objects are stored raw).
No branching or tags (just main).
No checkout or status (working tree isn’t manipulated).
Simplified formats (e.g., trees lack file modes).
But it’s enough to see Git’s soul: content-addressed storage, a commit graph, and staged changes.
That’s it for the day
While this is the simplest and initial version, you can learn there is more on the Github repo and also feel free to contribute new features.
Liked this article? Make sure to ❤️ click the like button.
Feedback or additions? Make sure to 💬 comment.
Know someone who would find this helpful? Make sure to 🔁 share this post.
Uhhh… git is already open[source], so why call your version OpenGit, implying that the original isn’t open[source]….?